字體:小 中 大
字體:小 中 大 |
|
|
|
| 2020/05/19 08:31:59瀏覽1150|回應0|推薦9 | |
因為百萬畫素的時代來臨,車牌辨識的工作不再只是辨識車牌的特寫照片,而是在複雜的全景影像中將如同隱藏在叢林中的車牌找出來,車牌不保證是正面水平的一個矩形目標,甚至可能髒污磨損或有陰影投在上面。 一般車牌辨識的論文都低估了這一段辨識過程的難度,大半篇幅都在寫「找到車牌」之後的處理程序,其實找到車牌之後的程序誰都會作,新一代車牌辨識真正的挑戰是從複雜背景中「找到車牌」的成功率與正確率!我們期待的是軟體可以和人一樣從環境中自行找到並辨識車牌。 因為從全景中找車牌這一段路變數實在太多太難解題,所以大家都期待人工智慧的大神來解救,當有人說機器學習類神經網路可以幫你鎖定目標時,大家都如同荒漠中看到甘泉,即使只是海市蜃樓都寧可相信這些技術真有神效!主要原因只是自己不會作,或者不想去解那麼難的題目,實在太累了! 我是極少數不信邪的人!還是堅持使用傳統的影像辨識流程去找車牌,我不相信有甚麼我不能理解的神奇演算法可以比我的知識推理更聰明!當我逐步研究打通傳統影像辨識方法到複雜影像辨識的路徑之後,以結果來看會感覺很神奇!很多似乎很難辨識的車牌都能被我找到,而且辨識成功,我不想唬人讓大家以為我有神力,我只是一個願意一鏟一鏟去移山的愚公而已。
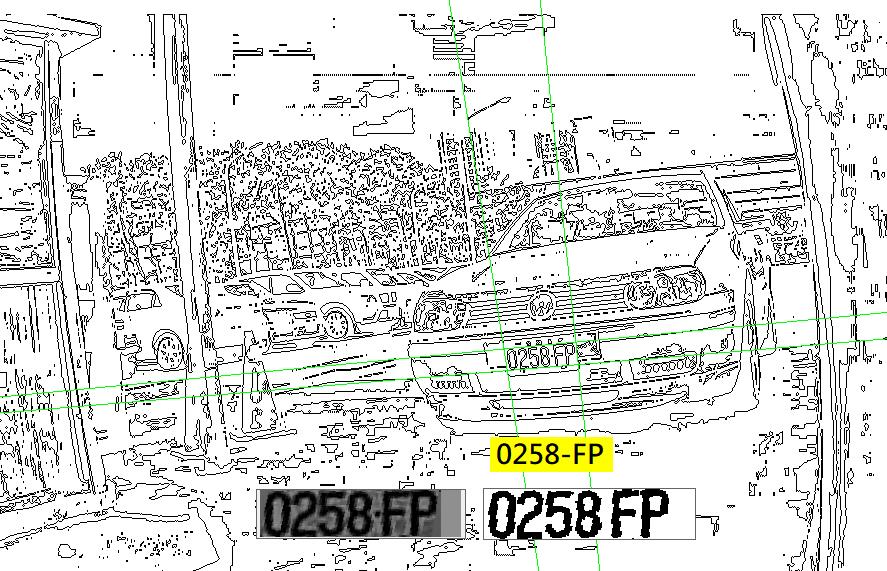
看看這張影像車牌狀況不太好,字元略小互相沾連又居於陰暗處,乍看之下一般人也不會立即看到車牌目標,如果要從明顯(高對比)的目標找起,確實要找一陣子才會輪到真正的車牌目標。我沒有未卜先知的能力,所以一開始我也完全不知道車牌的狀況,只能乖乖的作灰階→二值化→取輪廓→辨識目標。
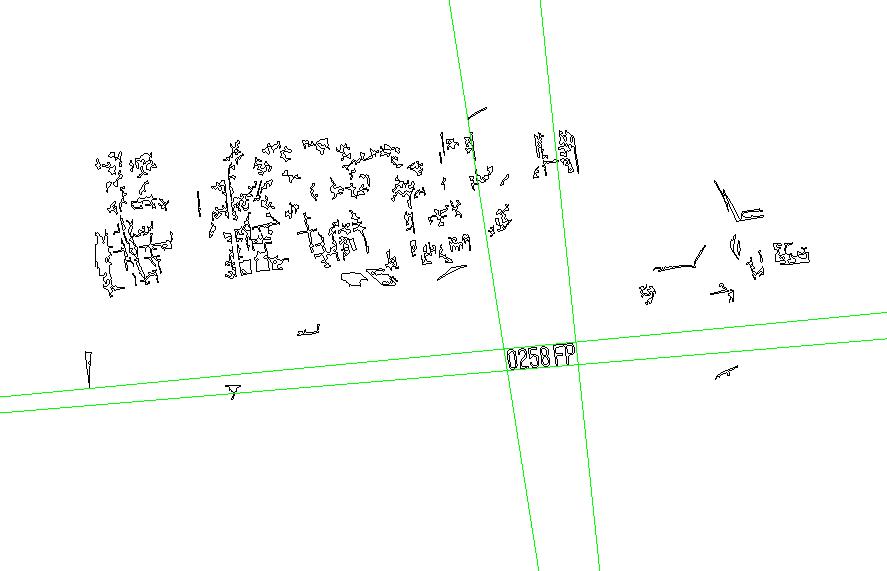
在我的實驗程式中,經過篩選後可能的字元目標如下圖,因為我還沒比對字元,我還「看不出」各個目標像甚麼字?只能以概略形狀大小,以及目標與背景的對比度來選擇目標,總共目標有107個,真正的車牌字元位居第54,88,89,92與104名。六個字為甚麼只有五個目標呢?因為F與P字是相連的!在此階段我無法直接知道它們其實是兩個字,只能用寬鬆一點的條件先選進來再說。
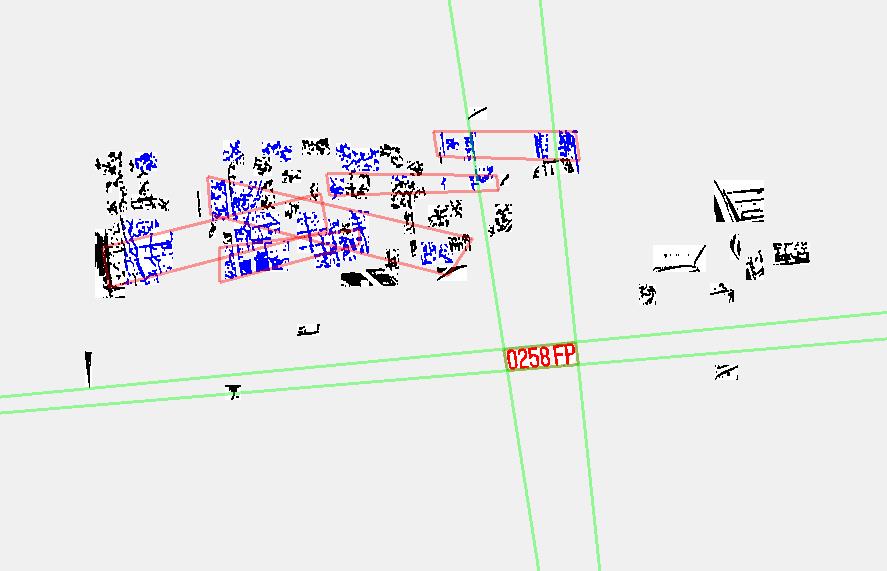
重點是:真正的車牌目標對比度是後段班,還沒比對字模之前我也不能直接知道它們才是真的字元,此時如果硬要比對字模,我們還不知道它們傾斜變形的程度,對不準的!還是必須先將它們組織成車牌,知道概略車牌形狀之後才能進一步作幾何校正,字元目標要抝正之後比對才會準確。 我怎麼知道哪幾個目標可能是車牌呢?就是盡量參考車牌字元組應該有的特性,譬如整齊排列,寬高相近,字距穩定等等。因為正常情況下車牌字元會比周邊目標明顯,所以當然是從對比高的目標找起。譬如這個案例中,我嘗試找到的第一組目標是排名(4,14,5,19,21,28)的六個目標,但實際上它們只是陽光下樹叢的光影雜訊,當然無法得到有意義的字元辨識結果,進行到某個程度我發現苗頭不對就會放棄再找下一組了! 因為真正合理的車牌字元很黯淡,對比度排得很後面,我是一路找到第七個組合才鎖定它們的!畫張圖給你看看我嘗試失敗的斑斑血跡,粉紅色框框就是嘗試抓錯的痕跡!
我就是這樣笨笨的一直在很亮的樹叢中找車牌,找了六次都不成功,最後才輪到位於陰影中真正的車牌!所以會花掉比車牌清楚時兩三倍的時間才辨識成功!如果你覺得我笨,我也一直覺得自己很笨,這幾天已經想了很多方法,希望能提前知道那些樹叢光影目標不是車牌,但目前還沒想到穩定聰明的演算法,如果不能更快知道那些目標不是字元,我就只能繼續嘗試作到發現不是我要的東西才放棄它們作下一步。 我的研究內容就是這樣的!每天都在想更聰明的演算法,用數學計算「模擬」出更多「人的智慧」可以快速認知資訊的過程。就是將我們的智慧拆解出來,加以數學化變成程式碼,這就是我認為真正的AI人工智慧研究!相對的,類神經網路只是模仿了人腦推測思考的「模式」,那是很基底的思考形式而已,距離人類「根據事實觀察」來因應解決問題的「智慧」,那只是末節。 真正需要投入大量時間人力研究的,其實是我們的腦袋看到事實現象時如何思考解決問題的過程。面對每一個問題,每一個領域,內容當然都不一樣的!就像我們不可能只學數學一個科目,就自動可以處理物理、化學與生物的所有問題一樣,其理至明!即使我們辨識不同影像時,腦袋裡所用的「程式」(智慧)都不會相同的!所以雖然我辨識車牌已經很厲害了,但人家問我會不會辨識人臉時,我的回答是很明確的:「不會!」 |
|
| ( 心情隨筆|工作職場 ) |